
Mit den Methoden apply, map und applymap können Funktionen in Python vektorwertig angewendet werden. Vektorwertig bedeutet, dass ein Objekt nicht Elementweise angesprochen wird, sondern, dass das gesamte Objekt in einem Prozessschritt transformiert wird. Insbesondere in Data-Science Anwendungen ist ein vektorwertiger Programmierstil nützlich. In diesem Beitrag erfahren Sie mehr über vektorwertiges Programmieren und darüber, was die 3 Funktionen leisten und worin sie sich unterscheiden.
Inhalt¶
- Implizite- und Explizite Schleifen
- Vektorwertige Programmierung
- apply, map und applymap
- map
- apply
- applymap
- Zusammenfassung
Implizite- und explizite Schleifen ¶
Wenn ein Objekt wie bspw. eine Liste einer Transformation unterzogen wird, dann kann dies über implizite oder explizite Schleifen erfolgen. Eine explizite Schleife ist durch den Entwickler geschriebener Quellcode, eine implizite Schleife ist bereits vorkompilierter Bytecode, der über einen Funktionsaufruf getriggert wird. Implizite Schleifen arbeiten in der Regel schneller als explizite Schleifen.
Explizite Schleifen auf Listen sind typischerweise for-Loops bzw. List-Comprehensions. Jedes Element der Liste wird bei einer expliziten Schleife angesprochen und verändert. Implizite Schleifen werden bspw. in numpy-arrays verwendet. Der User muss nun nicht mehr selbst jedes Element des arrays ansprechen und transformieren, sondern arbeitet Blockweise auf dem gesamten Objekt. Immer dann wenn der array in einer Expression angesprochen wird, sind alle Elemente adressiert.
# ----- Explizite Schleifen
## For-Loop
container = []
for i in [1,2,3]:
container.append(i ** 2)
## List-Comprehension
[i ** 2 for i in [1,2,3]]
# ----- Implizite Schleife mit numpy
import numpy as np
x = np.array([1,2,3])
x ** 2
Vektorwertige Programmierung ¶
Vektorwertige Programmierung nutzt implizite Schleifen. Umgekehrt bedeutet nicht-vektorwertige Programmierung, mit expliziten Schleifen zu arbeiten.
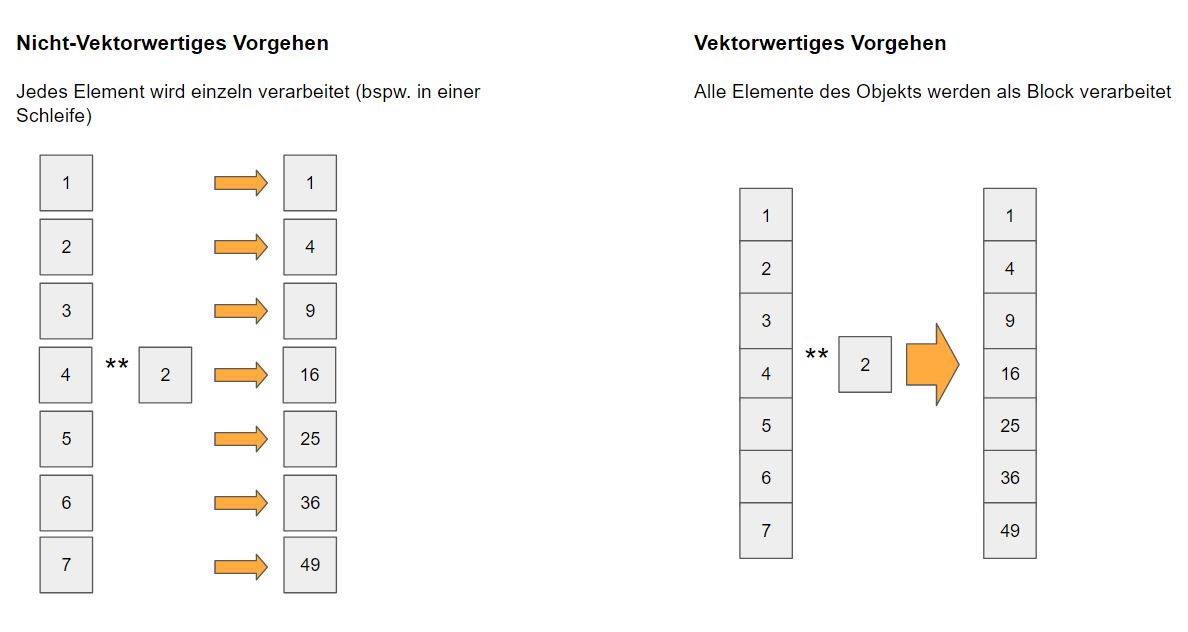
Insbesondere bei statistischen Daten sind vektorwertige Transformationen üblich. Statistische Daten liegen in einem Spreadsheet-Format vor, in der die Zeilen die Beobachtungsobjekte enthalten. Die Spalten führen dagegen die Eigenschaftsausprägungen (oder auch Attribute, Variablen, Features) der Objekte.
In der Abbildung sehen wir einen Beispieldatensatz, an dem eine Transformation der Variable Alter durchgeführt wird. Aus Alter wird das Geburtsjahr errechnet. Für einen Statistiker oder Datenanalysten ist es ein ganz natürliches Vorgehen, eine einzige Rechenoperation auf der Spalte Alter vorzunehmen und damit alle Zeilen des Datensatzes zu bearbeiten.

map, apply und applymap ¶
In Python sind implizite Schleifen in den Funktionen apply, map und applymap implementiert. Mit diesen können dementsprechend verktorwertige Operationen an Daten vorgenommen werden. Auch wenn sich die Funktionen ähneln, unterschieden sie sich in einigen Details. Welche das sind und wie die einzelnen Funktionen zu bedienen sind, wird im Folgenden vorgestellt.
map ¶
Mit der Build-In-Funktion map kann eine Funktion Elementweise auf Klassen angewendet werden, die über eine Methode __iter__ (Iterables, wie bspw. Listen, Series oder Dictionaries) verfügen.
myList = [1,2,3]
list(map(lambda x:x**2,myList))
myDict = {'a' : 1, 'b' : 2, 'c' : 3}
list(map(lambda x:x+'___suffix', myDict))
list(map(lambda x:x**2, myDict.values()))
Der Rückgabewert der Map-Funktion ist ein Objekt der Klasse map. Dieses wird lazy evaluated, also erst dann ausgewertet, wenn es wirklich gebraucht wird (hier soll es nicht um lazy evaluation gehen). Um die Werte nach dem Anwenden von map auszugeben, bietet sich (wie oben im Beispielcode) die Umwandlung in eine Liste an.
apply ¶
Mit der Funktion apply lässt sich die Split-Apply-Combine Technik auf die Objektklasse pandas.DataFrame umsetzen. Die Methode beschreibt, wie Daten in 3 Schritten aggregiert werden:
- Split: Die Daten werden aufgeteilt.
- Apply:: Auf die Teildatensätze wird eine numerische Aggregatsfunktion angewendet.
- Combine: Die Ergebnisse auf die Teildatensätze werden in einem Ausgabeobjekt zusammengefasst.
Die Funktion apply macht den Split (also die Aufteilung der Daten) anhand der Spalten oder der Zeilen im DataFrame. Durch das Argument axis wird auf eine der beiden Dimensionen indiziert (siehe hierzu die Dokumentation von pandas.DataFrame.apply).
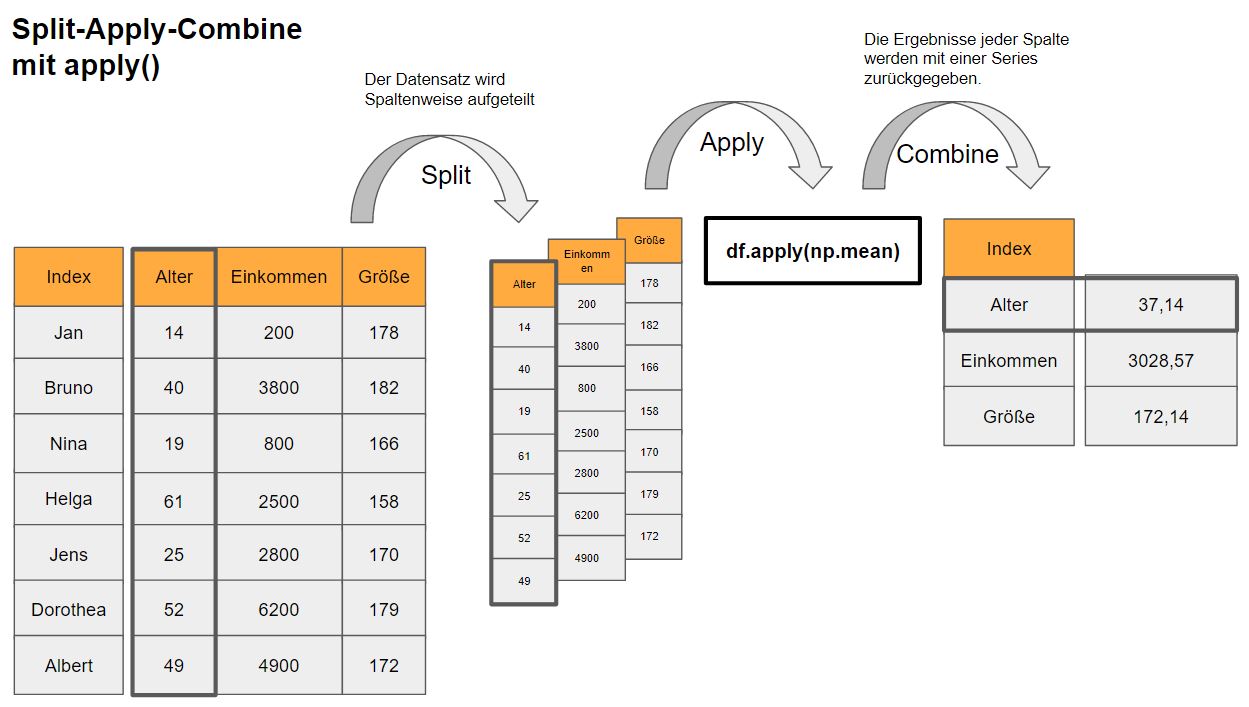
Als Faustregel können wir Anwender uns apply als Split-Apply-Combine-Werkzeug abspeichern und so nutzen. Dennoch kann die Funktion auch Elementweise angewendet werden – nämlich dann, wenn die Apply-Funktion auch auf den gesamten DataFrame angewendet werden kann. Beispielsweise würde ein Operator wie \** Elementweise vorgehen. Probieren Sie es aus:
import pandas as pd
df = pd.DataFrame({'col_A': [1,2,3],
'col_B': [7,8,9]})
df.apply(lambda x:x ** 2)
Zugegeben, diese Eigenart von apply macht die Funktion etwas obskur. Es bietet sich daher an, für elementweise Transformationen konsequent die Funktion applymap zu verwenden.
applymap ¶
Die Funktion applymap geht bei der Transformation der Daten elementweise vor – die Funktion wird also auf jede Zelle des DataFrames angewendet. Die Struktur der Ursprungsdaten (Anzahl der Zeilen und Spalten) bleibt dadurch erhalten.

Mit dem unten angefügten Beispielcode aus der offiziellen pandas-Dokumentation lässt sich das Verhalten von applymap nachvollziehen.
import pandas as pd
# Erstellen eines DataFrames mit Zufallszahlen
df = pd.DataFrame(np.random.randn(3, 3))
# Runden der Zahlen auf 2 Nachkommastellen
df = df.applymap(lambda x: '%.2f' % x)
Zusammenfassung ¶
Die 3 Funktionen apply, map und applymap sind in ihren Fähigkeiten nicht trennscharf und deswegen etwas schwierig auseinanderzuhalten. Zusammenfassend (und auch wenn andere Lösungswege existieren) lassen sich die Funktionen auf folgende Weise in eine Ordnung bringen:
