
Pandas und sein Datentyp DataFrame ist eines der zentralen Data-Science Werkzeuge in Python. Die Selektion von Daten um Subsets zu erstellen oder Werte zu aktualisieren, gehört dabei zu den elementarsten Techniken, mit denen der Data-Scientist umzugehen hat.
Die in pandas hinterlegten Konzepte der Datenselektion sind mächtig, aber gleichermaßen komplex. In diesem Beitrag werden die Methoden der Datenselektion in DataFrames vorgestellt und diskutiert.
Inhalt¶
- Indizieren, Indexieren, Selektieren
- Der DataFrame
- Vorüberlegungen zur Indizierung
- Indizierungstechniken für DataFrames
- Welche dieser Methoden ist zu bevorzugen?
Indizieren, Indexieren, Selektieren ¶
Das Selektieren (auch Indexieren oder Indizieren) von Daten ist nichts anderes, als einen speziellen Typ von Filter anzuwenden. 2 Techniken sind dabei zu unterscheiden:
Zum einem kann dieser Filter die explizite Ansprache der relevanten Daten über ihre Position oder ihren Namen sein. Bei dieser Form der Indizierung wird die Frage beantwortet, welcher Wert hinter bestimmten Positionen steckt.
Die zweite Form der Indizierung ist das Filtern von Daten mit Hilfe von booleschen Masken. Hier wird die Frage beantwortet, welche Position hinter einem bestimmten Wert steckt. Bei dieser Technik wird zunächst eine logische Abfrage an die Daten gestellt und anschließend mit der booleschen Rückgabe der Datensatz gefiltert. Python interpretiert den Wert True für diejenigen Zeilen, die ausgewählt werden sollen.
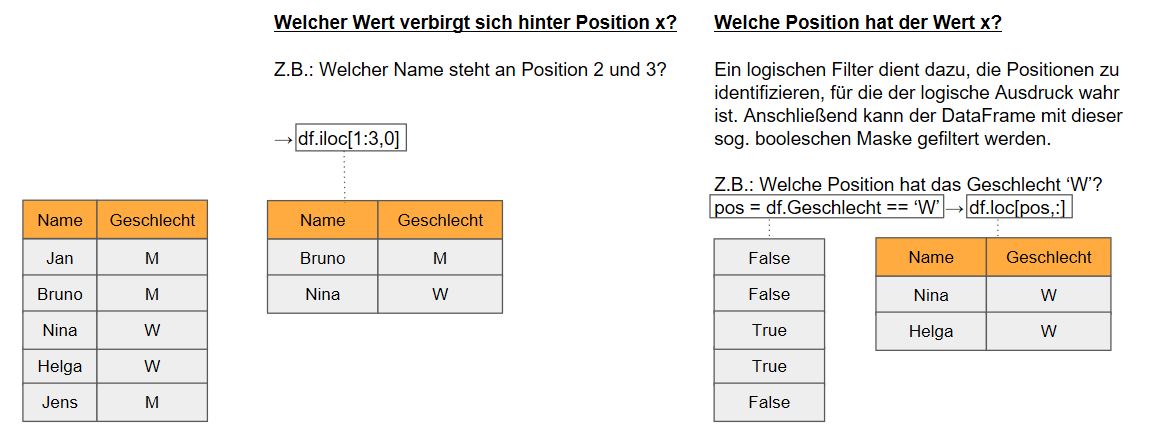
In pandas lösen Indizierungen 2 zentrale Anforderungen innerhalb des Datenmanagements:
- Erstellen von Subsets als Kopie der originalen Daten.
- Aktualisieren eines Subsets von Daten im DataFrame (als In-Place-Operation).

Der DataFrame ¶
Bevor wir uns um die Indizierung von Daten kümmern, halten wir uns vorher noch einmal die Strukturen eines DataFrames vor Augen.
Ein DataFrame ist ein Dictionary-Ähnliches Konstrukt, mit Variablenlabels als Keys und Series-Objekten als Values. Die Spalten sind im DataFrame als Attribute abgelegt. Die folgende Abbildung zeigt den schematischen Aufbau eines DataFrames:
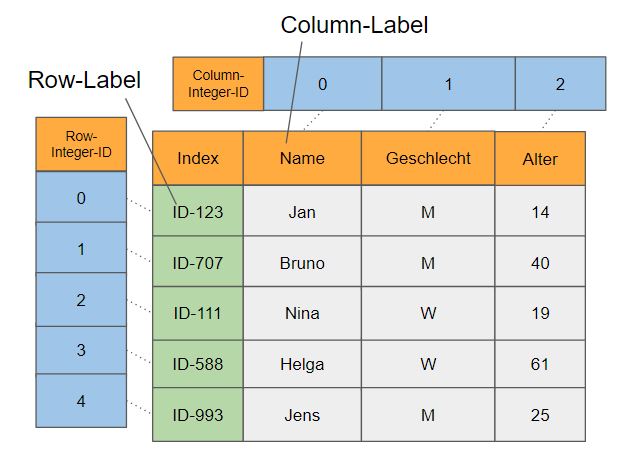
Aus der Abbildung halten wir folgendes fest:
- Ein DataFrame verfügt über Zeilen und Spalten und ist damit 2-dimensional.
- Er verfügt immer über einen Zeilenindex aus Integerwerten, beginnend bei 0 (Integerindex).
- Die Zeilen im DataFrame sind gelabelt (wird ihnen kein explizites Label übergeben, werden die Zeilen per Default mit Integerwerten bezeichnet) (Labelindex).
- Er verfügt immer über einen Spaltenindex aus Integerwerten, beginnend bei 0 (Integerindex).
- Die Spalten des DataFrames verfügen immer über ein Label (Labelindex).
Vorüberlegungen zur Indizierung ¶
Grundsätzlich muss sich der Analyst vor der Indizierung von Daten über folgende Sachverhalte Klarheit verschaffen:
- Soll ein Subset erstellt werden, oder sollen Werte (In-Place) aktualisiert werden?
- Sollen die Spalten und/oder Zeilen die er auswählen möchte mit ihrem Integerindex oder mit ihrem Label angesprochen werden?
- Werden selektive Indizierungen durchgeführt, oder wird über Spannweiten Indiziert? [Selektive Indizierung meint die explizite Ansprache von Zeilen und Spalten. In der Spannweiten-Indizierung wird ein Bereich (von-bis) definiert.]
- Welches Format soll der Rückgabewert der Indizierung haben – DataFrame oder Series?
Indizierungstechniken für DataFrames ¶
In pandas existieren unterschiedliche Techniken, um Daten in DataFrames zu indizieren. Zur Verfügung stehen die numpy-Notation, die DataFrame-Properties .iloc, .loc und .at sowie der zum Python-Standard gehörige Attribute-Access-Operator. Je nachdem welche Ziele mit der Indizierung verfolgt werden, ist die eine oder andere Methode von Vorteil.
Um die verschiedenen Techniken vorzustellen, erstellen wir uns einen kleinen Beispieldatensatz.
import pandas as pd
df = pd.DataFrame({'Name' : ["Peter", "Karla", "Anne", "Nino", "Andrzej"],
'Alter': [34, 53, 16, 22, 61],
'Nationalität': ["deutsch", "schweizerisch", "deutsch", "italienisch", "polnisch"],
'Gehalt': [3400, 4000, 0, 2100, 2300]},
index = ['ID-123', 'ID-462', 'ID-111', 'ID-997', 'ID-707'],
columns = ['Name', 'Alter', 'Nationalität', 'Gehalt'])
df
numpy-Indexing¶
In Python existiert für den Zugriff auf Daten die Standardnotation x[y]. Dieser sog. Index-Operator (eckige Klammer) wurde in numpy erweitert, um auf mehrdimensionale Objekttypen zuzgreifen. Pandas ist wiederum eine Erweiterung von numpy und unterstützt den mehrdimensionalen Zugriff auf Daten in gleicher Weise wie in der numpy-Implementierung.
Zum Verständnis der numpy-Indizierung auf DataFrames hier ein paar grundlegende Funktionsweisen:
- Sollen Spalten ausgewählt werden, müssen dem Indexing-Operator die entsprechenden Label übergeben werden.
- Sollen Zeilen ausgewählt werden, wird innerhalb des Indexing-Operators mit dem Slicing-Operator (der Doppelpunkt) gearbeitet.
- Soll ein Subset mit Zeilen und Spalten erstellt werden, geschieht dies sequentiell, indem der Indexing-Operator jeweils für Zeilen und Spalten verwendet wird.
- Eine Indizierung erzeugt einen View aus den originalen Daten.
- Zuweisungen unter Zuhilfenahme von numpy-Indizierungen sollten vermieden werden. Für Zuweisungen .loc und .iloc verwenden.
- Die Indizierung einer Spalte returniert eine Series.
- Wird dem Indexing-Operator eine Liste übergeben, wird ein DataFrame returniert.
- Der Slicing-Operator definiert einen Bereich in der Form: [von:bis:Schrittweite]
[Anmerkung: Zur besseren Lesbarkeit enthält der Beitrag lediglich auführbaren Quellcode und nicht die Ausgabeobjekte.]
# Auswahl von Spalten
df['Name'] # Rückgabeobjekt ist eine Series.
df[['Name']] # Rückgabe ist ein DataFrame
# Auswahl von Zeilen --> Bei der Zeilenindizierung wird immer der Slicing-Operator verwendet.
df[1:2] # Rückgabe ist die erste Zeile mit dem Indexwert 1.
df[0:5:2] # Jede zweite Zeile im Bereich 0 bis 5 wählen.
df[:2] # Die Zeilen mit Integerindex 0 und 1 werden angezeigt.
df[-2:] # Letzten beiden Zeilen anzeigen lassen.
df[::-1] # Sortierung umdrehen.
# Sowohl Zeilen als auch Spalten selektieren
df['Name'][2] # Rückgabe ist ein einzelner Wert gleichen Typs der Spalte, aus der er stammt.
df['Name'][2:4] # Rückgabe ist eine Series.
df[['Name','Nationalität']][2:4] # Rückgabe ist ein DataFrame.
# Eine Zuweisung in dieser Notation sollte vermieden werden (siehe Warnung). Bei Zuweisungen loc und iloc verwenden.
df['Name'][2] = "Annemarie"
# Indizierung mit Masken
df[[True,False,True,False,False]] # Bei der Indizierung mit booleschen Werten werden Zeilen indiziert.
df[df['Alter'] > 30] # Anwenden eines Filters
# Kurze Zusammenfassung:
df[[1,2]] # Integerwerte indizieren die Zeilen
df[[True,False,True,False,False]] # Boolesche Werte indizieren Zeilen
df[['Name','Gehalt']] # Column-Labels indizieren die Spalten
df['ID-111'] # Indizierung über Zeilenlabel returniert einen Key-Error. Dies liegt daran, dass Zeilennamen in numpy arrays nicht implementiert sind.
Eine Dokumetation über die Indizierungstechniken in numpy finden Sie hier.
pandas-Indexing über Properties¶
In Pandas wurde das numpy Konzept ausgebaut, um auch über Indizes auf die Daten zuzugreifen. 2-Properties (.iloc und .loc) stehen für den Daten-Access über den Integer- bzw. den Labelindex zur Verfügung. Daneben existiert für das Indizieren eines einzelnen Wertes die .at-Property.
Achtung Fehlergefahr: Die Slicing-Technik zwischen .loc und .iloc unterscheidet sich! Während .iloc die erste Ziffer in den View einschließt und die zweite Ziffer aus dem View ausschließt, werden bei der Labelindizierung mit .loc die Zeilen “bis einschließlich” ausgewählt.
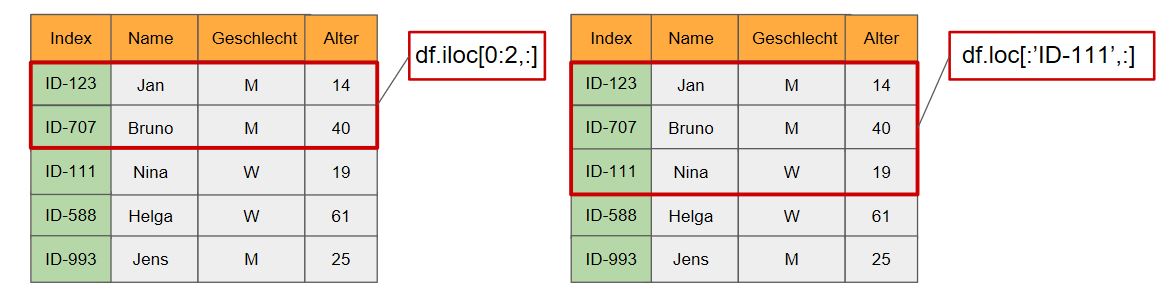
.loc – Labelindizierung¶
# Zeilenindizierung
df.loc['ID-123'] # Rückgabeobjekt bei einer Zeile ist eine Series
df.loc[['ID-123']] # Analog zur numpy-Indizierung: Wird eine Liste übergeben, wird ein DataFrame returniert
df.loc[['ID-123'],:] # Gleiche Abfrage wie eine Zeile zuvor, aber expliziter und daher (wie ich finde) stilistisch schöner
df.loc[['ID-123','ID-111'],:] # Rückgabe ist ein DataFrame mit 2 Zeilen
# Spaltenindizierung
df.loc[:,'Name'] # Rückgabe ist eine Series
df.loc[:,['Name'] # Rückgabe ist ein DataFrame
df.loc[:,'Name':'Name'] # Spannweitenindizierung auch über die Label möglich. Rückgabe ist ein DataFrame (wie obige Zeile)
# Indiziere Zeile und Spalte
df.loc['ID-123','Name'] # Rückgabe ist der *type* der entsprechenden Zelle
df.loc[['ID-123','ID-111'],'Name'] # Rückgabe ist eine Series
df.loc[['ID-123','ID-111'],['Name']] # Rückgabe ein ein DataFrame
df.loc[:'ID-111',] # Alle Zeilen bis einschließlich dem explizit gesuchten Fall
df.loc[['ID-123','ID-111'],'Name':'Alter'] # Hier wird eine Range angegeben: Von Name bis Alter
# Indizierung mit Maske
df.loc[df['Name'] == 'Peter',:]
Für den Fall, dass eine Ausschluss-Indizierung vorgenommen werden soll, existiert sowohl für Index- als auch für Spaltenlabel die Methode difference. Ausschluss-Indizierung meint: Alle Zeilen/Spalten nur nicht Zeile/Spalte x.
df.index.difference(['ID-123'])
df.columns.difference(['Name'])
# Beispiel:
df.loc[df.index.difference(['ID-123']), df.columns.difference(['Name'])]
.iloc – Integerindizierung¶
# ----- Zeilenindizierung
df.iloc[1,] # --> Rückgabewert ist eine Series
df.iloc[1,:] # --> Gleicher Ausdruck wie obige Zeile, aber explizite Schreibweise
df.iloc[1:2,:] # --> Wird in der Zeilenindizierung der Slicing-Operator verwendet, ist der Rückgabewert immer ein DataFrame
df.iloc[[1],:] # --> Wird in der Zeilenindizierung eine Liste übergeben, ist der Rückgabewert ebenfalls immer ein DataFrame
# ----- Spaltenindizierung
df.iloc[:,1] # --> Rückgabewert ist eine Series
df.iloc[:,0:1] # --> Wird in der Spaltenindizierung der Slicing-Operator verwendet, ist der Rückgabewert immer ein dataframe
df.iloc[:,[0]] # --> Wird in der Spaltenindizierung eine Liste übergeben, ist der Rückgabewert immer ein dataframe
df.iloc[[1,-1],[2,3]] # --> Kombiniert
df.iloc[-1,::-1] # Letzte Zeile ausgewählt, Reihenfolge der Spalten umgedreht; Rückgabewert ist eine Series
df.iloc[0:5:2,:] # Gewohnte Zeilenindizierung aus numpy: Zeile 0 bis (exklusive) Zeile 5 mit Schrittweite 2 auswählen.
# Indizierungen mit Masken sind nur über .loc verfügbar.
.at – Einzelwertabfrage¶
# .at erwartet Labels - analog zu .loc
df.at['ID-111','Name']
# Wenn dennoch über Integers abgefragt werden soll, kann dies auf diesem Weg erfolgen:
df.at[df.index[2],df.columns[0]]
Gemischte Indizierung über Integer- und Labelindex¶
Recht häufig kommt es bei der Auswahl von Zeilen und Spalten vor, dass eine Mischform von Integer- und Labelindizierung vorgenommen werden soll. Beispielsweise sollen die Zeilen über ihre Position ausgewählt werden und die Spalten über ihr Label. Um solch eine Mischform in der Indizierung zu nutzen, kann .iloc in Kombination mit der Utility-Methode get_loc() verwendet werden. Die Methode get_loc() existiert sowohl für den Zeilen- als auch für den Spaltenindex.

df.iloc[df.index.get_loc('ID-111'), 0] # Gemischte Indizierung: Zeilenlabel und Spalteninteger
df.iloc[0,df.columns.get_loc('Name')] # Gemischte Indizierung: Zeileninteger und Spaltenlabel
# Den Methoden get_loc() für Index und Spalten kann keine Liste von Werten übergeben werden. Für die Suche nach mehreren Positionen kann folgende Technik verwendet werden:
label = ['ID-123', 'ID-111']
integerLocations = [df.index.get_loc(i) for i in label]
df.iloc[integerLocations, 0]
Eine weitere Möglichkeit Integer- und Labelindizierung zu kombinieren, besteht durch das Aneinanderhängen von .loc und .iloc:
df.loc[:,['Name','Gehalt']].iloc[0:2,:]
df.iloc[0:2,:].loc[:,['Name','Gehalt']]
Attribute-Access-Operator¶
Eine weitere Methode um auf DataFrames zu indizieren, ist der in Python standardmäßig implementierte Access-Operator (.). Da es sich bei den Spalten eines DataFrames um Attribute handelt, können diese entsprechend über den gewohnten Attribute-Access mit df.ColumnName abgerufen werden. Auch hierbei handelt es sich um eine Indizierungstechnik: Wir filtern Daten über die explizite Ansprache der einzelner Spalten. Der Attribute-Access sollte allerdings nur dazu verwendet werden, Subsets aus dem DataFrame abzufragen. Für Zuweisungen sollen .iloc und .loc verwendet werden.
df.Name # --> Rückgabewert ist ein Series
Welche dieser Methoden ist zu bevorzugen? ¶
Grundsätzlich sind die Properties .iloc und .loc gegenüber den anderen Verfahren zu bevorzugen – auch wenn man bei dieser Aussage Einschräkungen machen muss.
Zum Thema Performance¶
Wenn wir Programme schreiben, wollen wir natürlich schnelle Ausführungszeiten erreichen und Performance spielt bei der Entwicklung von Quellcode daher immer eine mehr oder weniger gewichtige Rolle. Und auch bei der Indizierung sind die vorgestellten Methoden mehr oder weniger schnell darin, bestimmte Daten abzufragen.
Wenn es beispielsweise um den Zeilenzugriff geht, sind .iloc und .loc performanter als die anderen vorgestellten Methoden. Bei der Spaltenindizierung ist jedoch die Array-Indizierung aus numpy schneller, ebenso der Attribute-Access. Da jedoch ein Datensatz üblicherweise aus mehr Zeilen als Spalten besteht, bleibt es bei der Faustregel, .iloc und .loc zu präferieren. Ein anderes Beispiel betrifft die Properties .loc und .at. Einen einzelnen Wert anzusprechen, ist mit beiden Methoden möglich. Um ein vielfaches schneller ist jedoch .at.
In der Programmierung kann Performance auf 2 Ebenen gemessen werden. Zum einen in der Prozessierungs-Performance – d.h. in der Zeitmessung darüber, wie lange der Prozessor braucht, um bestimmten Code auszuführen. Zum anderen in der Entwicklerzeit. Diese bemisst sich durch die Zeit, die benötigt wird, um Quellcode zu schreiben sowie der Onboarding-Zeit für den Quellcode. Onboarding-Zeit ist Zeit, die ein Entwickler gegebenenfalls benötigt, um den Quellcode zu verstehen (bspw. wenn ein neuer Entwickler in das Projekt einbezogen wird, oder nach einiger Zeit Änderungen vorgenommen werden sollen).
Performanceoptimierung heißt, zwischen Prozessierungs-Performance und Entwicklerzeit einen optimalen Trade-Off zu finden. Wenn die Software nicht schnell laufen muss, aber dafür eher schnell entwickelt werden soll (was in den meisten Projekten erfahrungsgemäß der Fall ist) empfiehlt es sich, einen sauberen Stil zu pflegen um Les- und Nachvollziehbarkeit zu gewährleisten. Erst wenn Ausführungsgeschwindigkeit ein tatsächlicher Faktor innerhalb des Projekts wird, sollte die Abfragetechnik optimiert werden.
Gewohnheiten entwickeln¶
In meinen Trainigs empfehle ich, sich innerhalb des Entwickler- oder Data-Science Teams auf eine bestimmte Programmierstil-Konvention zu einigen – bspw. nach PEP 8 zu programmieren. Gleichermaßen gilt, sich auf eine Form der Indizierung zu einigen und diese konsequent in nicht-performancekritischen Projekten umzusetzen. Und auch wenn Sie Projekte alleine bearbeiten, sollten Sie sich eine bestimmte Indizierungsform angewöhnen. Ich persönlich habe, bevor ich in Python programmierte, viel in R gearbeitet. In meinem Code verwende ich daher (weil dies der R-Indizierung ähnelt) den Attribute-Access wenn ich einzelne Spalten anspreche. Wenn ich einzelne Werte anspreche, versuche ich .at zu verwenden. In allen anderen Fällen arbeite ich mit .iloc und .loc. Und diese versuche ich so explizit wie möglich zu nutzen. Auch wenn die folgenden Zeilen das gleiche Objekt returnieren:
df.loc[['ID-123','ID-111']]
df.loc[['ID-123','ID-111'],:]
präferiere ich die zweite Variante, da sie expliziter ist. ‚Explicit is better than implicit‘ heißt es schließlich auch im Zen of Python.