
Kategoriale Daten werden in der Regel über Auszählungen analysiert. Wie sie einfache Häufigkeits- bis hin zu komplexen Kreuztabellen mit pandas erstellen, erfahren Sie in diesem Beitrag.
Inhalt
crosstab und pivot_table¶
Grundsätzlich liefert pandas 2 Instrumente, mit denen sich komplexere Häufigkeitsauszählungen umsetzen lassen. Dies sind die Funktionen crosstab und pivot_table. Beide Methoden unterscheiden sich dabei in einigen Nuancen:
- crosstab:
- crosstab ist eine Funktion.
- Input sind einzelne Spalten aus Arrays oder DataFrames.
- Die Default-Aggregatsfunktion ist ‚len‘.
- pivot_table:
- pivot_table ist eine Klassenmethode von DataFrame.
- Input muss vom Typ DataFrame sein.
- Die Default-Aggregatsfunktion ist ‚mean‘.
- pivot_table arbeitet mit den gesamten Daten.
Da crosstab expliziter arbeitet als pivot_table, empfehle für die Anwendung von Häufigkeitsauszählungen diese Funktion.
Wie wir noch sehen werden, ist crosstab sehr flexibel: Neben Auszählungen einzelner Spalten können Kreuztabellen und verschachtelte Kreuztabellen erzeugt werden. Auch Aggregationen mit statistischen Funktionen lassen sich mit crosstab umsetzen.
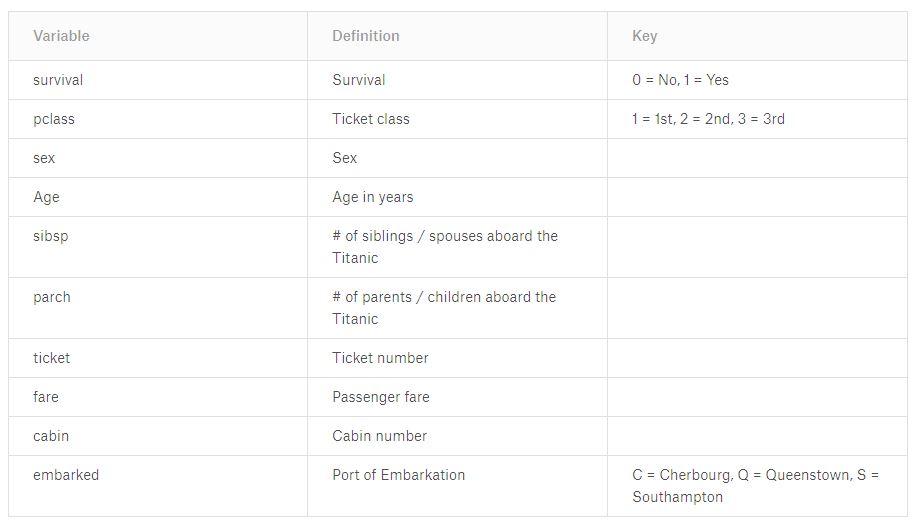
Der Beispieldatensatz ‚titanic‘¶
Die Methode crosstab wird an dem Beispieldatensatz ‚titanic‘ vorgeführt. Wenn Sie den hier dargestellten Quellcode lokal ausführen möchten, können Sie sich dazu den Datensatz hier downloaden.
Die ersten 5 Zeilen des Datensatzes sind unten dargestellt. Außerdem finden Sie weiter unten eine Kurzbeschreibung der Daten.
import pandas as pd
titanic = pd.read_csv("../__data/Titanic.csv")
titanic.head()
Einfache Auszählung einzelner Spalten¶
Vielleicht ist Ihnen die Series-Methode value_counts bekannt. Diese zählt die Werte einer Series aus und returniert wiederum eine Series. Crosstab kann diesen Zweck in gleicher Weise erfüllen, mit dem einen Unterschied, nicht eine Series, sondern einen DataFrame zu returnieren.
titanic['sex'].value_counts() # Returniert eine Series
# Returniert einen DataFrame
pd.crosstab(index=titanic['sex'], # Die Ausprägungen der Spalte sex werden Zeilenindex
columns="Count") # Wird ein einfacher String übergeben, ist dieser das Spaltenlabel
# Wie oben, nur Zeilen und Spalten vertauscht:
pd.crosstab(index='Count', # Wird ein einfacher String übergeben, ist dieser das Zeilenlabel
columns=titanic['sex']) # Die Ausprägungen der Spalte sex werden Spaltenlabel
Kreuztabellen¶
Um Kreuztabellen zu erstellen, werden die Argemente index (entspricht den Zeilen der Tabelle) und columns (die Spalten) mit Array-Objekten besetzt.
pd.crosstab(index=titanic['sex'], columns=titanic['pclass'])
Verschachtelte Kreuztabellen¶
Um Kreuztabellen zu schachteln, können den Argumenten index und columns Listen mit Array-Objekten übergeben werden.
pd.crosstab(index=[titanic['pclass'], titanic['sex']], columns='Count')
Aggregationen¶
Auch Datenaggregationen können mit crosstab vorgenommen werden. Dem Argument values wird dazu ein Array-Objekt mit Werten übergeben, welche mit den Funktionen aus dem Argument aggfunc ausgewertet werden. Wie in dem Beispiel zu sehen ist, können auch mehrere Aggregationsfunktionen als Liste übergeben werden. Wie in dem Beispiel leider auch zu sehen ist, können dem Argument columns nicht mehrere Spaltenlabel übergeben werden – hier hat die Funktion crosstab noch Verbesserungspotenzial.
import numpy as np
pd.crosstab(index=titanic['sex'], columns="Aggregat", values=titanic['age'], aggfunc=[len,np.mean])
Randverteilungen und Prozentwerte¶
Fortgeschrittene Tabellen enthalten bspw. Randverteilungen und Prozentwerte. Die Randverteilung wird der Tabelle mit dem Argument margins=True hinzugefügt. Mit applymap wird jede Zelle der Tabelle in den entsprechenden Prozentwert transformiert. (Erfahren Sie hier mehr über applymap.)
pd.crosstab(index=titanic['sex'], columns=titanic['pclass'], margins=True).applymap(lambda r: r/len(titanic))
Sollen die Zeilen oder Spaltenprozente berechnet werden, kann dies nach dem Split-Apply-Combine Ansatz geschehen. Split-Apply-Combine wird in Python mit der Funktion apply umgesetzt.
# Spaltenprozente:
pd.crosstab(index=titanic['sex'], columns=titanic['pclass'], margins=False).apply(lambda zeile: zeile/zeile.sum(), axis=0)
# Zeilenprozente:
pd.crosstab(index=titanic['sex'], columns=titanic['pclass'], margins=False).apply(lambda zeile: zeile/zeile.sum(), axis=1)
Weitere Web-Referenzen zum Thema¶
Pandas Dokumentation zu crosstab
Pandas Dokumentation zu pivot_table